The first transistors were point contact devices, not far from the cats-whiskers of early radio receivers. They were fragile and expensive, and their performance was not very high. The transistor which brought the devices to a mass audience through the 1950s and 1960s was the one which followed, the alloy diffusion type. [Play With Junk] has a failed OC71 PNP alloy diffusion transistor, first introduced in 1957, and has cracked it open for a closer look.
Inside the glass tube is a small wafer of germanium crystal, surrounded by silicone grease. It forms the N-type base of the device, with the collector and emitter being small indium beads fused into the germanium. The junctions were formed by the resulting region of germanium/indium alloy. The outside of the tube is pained black because the device is light-sensitive, indeed a version of this transistor without the paint was sold as the OCP71 phototransistor.
Lithium-ion cells deliver very high energy densities compared to many other battery technologies, but they bring with them a danger of fire or explosion if they are misused. We’re mostly aware of the battery conditioning requirements to ensure cells stay in a safe condition, but how much do we know about the construction of the cells as a factor? [Lumafield] is an industrial imaging company, and to demonstrate their expertise, they’ve subjected a large number of 18650 cells from different brands to a CT scan.
The construction of an 18650 sees the various layers of the cell rolled up in a spiral inside the metal tube that makes up the cell body. The construction of this “jellyroll” is key to the quality of the cell. [Lumafield’s] conclusions go into detail over the various inconsistencies in this spiral, which can result in cell failure. It’s important that the edges of the spiral be straight and that there is no electrode overhang. Perhaps unsurprisingly, they find that cheap no-name cells are poorly constructed and more likely to fail, but it’s also interesting to note that these low-quality cells also have fewer layers in their spiral.
We hope that none of you see more of the inside of a cell in real life than you have to, as they’re best left alone, but this report certainly sheds some light as to what’s going on inside a cell. Of course, even the best cells can still be dangerous without protection.
De autovossenjacht gaat helaas niet door op 20 september.
Reden hiervoor is dat de organisatie slechts één aanmelding heeft binnengekregen.
Wij vinden het erg jammer dat er niemand warm loopt om mee te doen en hopen dat er meer aanmeldingen zullen volgen voor de QSO party op zondag 23 november a.s.
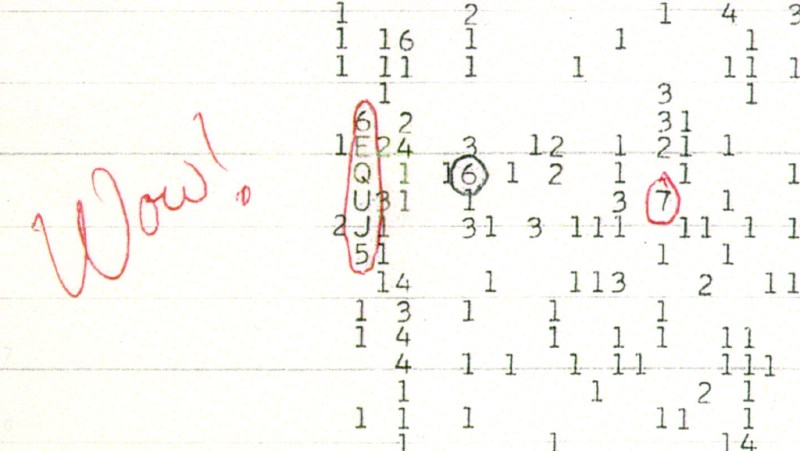
As you might expect, the University of Puerto Rico at Arecibo has a fascination with radio signals from space. While doing research into the legendary “Wow! Signal” detected back in 1977, they realized that the burst was so strong that a small DIY radio telescope would be able to pick it up using modern software-defined radio (SDR) technology.
This realization gave birth to the Wow@Home project, an effort to document both the hardware and software necessary to pick up a Wow! class signal from your own backyard. The University reasons that if they can get a bunch of volunteers to build and operate these radio telescopes, the resulting data could help identify the source of the Wow! Signal — which they believe could be the result of some rare astrophysical event and not the product of Little Green Men.
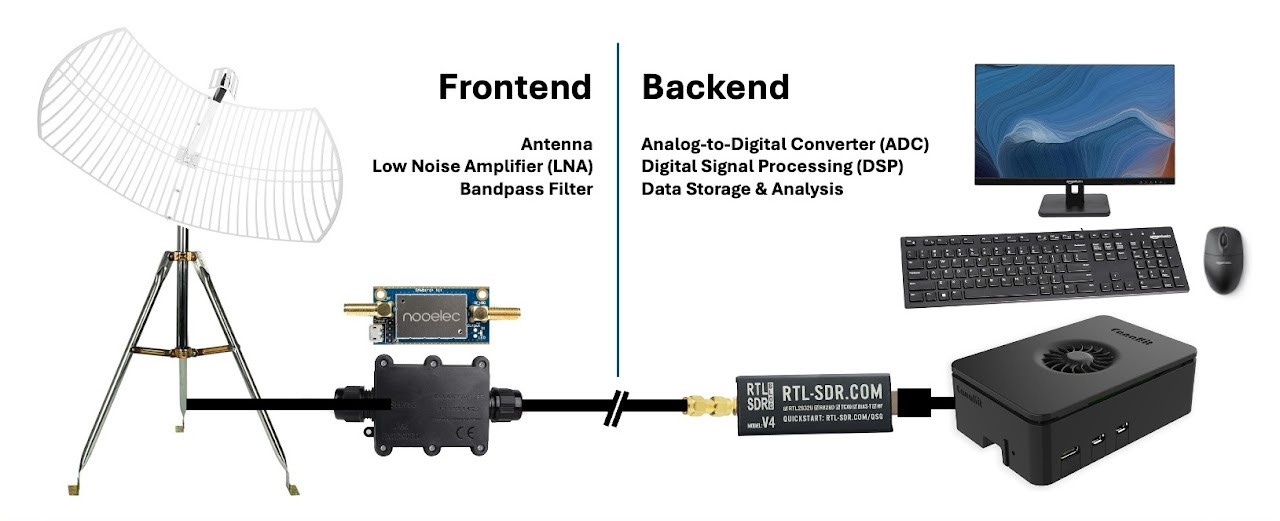
Ultimately, this isn’t much different from many of the SDR-based homebrew radio telescopes we’ve covered over the years — get a dish, hook your RTL-SDR up to it, add in the appropriate filters and amplifiers, and point it to the sky. Technically, you’re now a radio astronomer. Congratulations. In this case, you don’t even have to figure out how to motorize your dish, as they recommend just pointing the antenna at a fixed position and let the rotation of the Earth to the work — a similar trick to how the legendary Arecibo Observatory itself worked.
The tricky part is collecting and analyzing what’s coming out of the receiver, and that’s where the team at Arecibo hope to make the most headway with their Wow@Home software. It also sounds like that’s where the work still needs to be done. The goal is to have a finished product in Python that can be deployed on the Raspberry Pi, which as an added bonus will “generate a live preview of the data in the style of the original Ohio State SETI project printouts.” Sounds cool to us.
If you’re interested in lending a hand, the team says they’re open to contributions from the community — specifically from those with experience RFI shielding, software GUIs, and general software development. We love seeing citizen science, so hopefully this project finds the assistance and the community it needs to flourish.
For the most part, the Radio Apocalypse series has focused on the radio systems developed during the early days of the atomic age to ensure that Armageddon would be as orderly an affair as possible. From systems that provided backup methods to ensure that launch orders would reach the bombers and missiles, to providing hardened communications systems to allow survivors to coordinate relief and start rebuilding civilization from the ashes, a lot of effort went into getting messages sent.
Strangely, though, the architects of the end of the world put just as much thought into making sure messages didn’t get sent. The electronic village of mid-century America was abuzz with signals, any of which could be abused by enemy forces. CONELRAD, which aimed to prevent enemy bombers from using civilian broadcast signals as navigation aids, is a perfect example of this. But the growth of civil aviation through the period presented a unique challenge, particularly with the radio navigation system built specifically to make air travel as safe and reliable as possible.
Balancing the needs of civil aviation against the possibility that the very infrastructure making it possible could be used as a weapon against the U.S. homeland is the purpose of a plan called Security Control of Air Traffic and Air Navigation Aids, or SCATANA. It’s a plan that cuts across jurisdictions, bringing military, aviation, and communications authorities into the loop for decisions regarding when and how to shut down the entire air traffic system, to sort friend from foe, to give the military room to work, and, perhaps most importantly, to keep enemy aircraft as blind as possible.
Highways in the Sky
As its name suggests, SCATANA has two primary objectives: to restrict the availability of radio navigation aids during emergencies and to clear the airspace over the United States of unauthorized traffic. For safety’s sake, the latter naturally follows the former. By the time the SCATANA rules were promulgated, commercial aviation had become almost entirely dependent on a complex array of beacons and other radio navigation aids. While shutting those aids down to deny their use to enemy bombers was obviously the priority, safety demanded that all the planes currently using those aids had to be grounded as quickly as possible.
The Rogue Valley VOR station in Table Rock, Oregon. According to the sectional charts, this is a VORTAC station. Source: ZabMilenko, CC BY 3.0, via Wikimedia Commons.
Understanding the logic behind SCATANA requires at least a basic insight into these radio navigation aids. The Federal Communications Commission (FCC) has jurisdiction over these aids, listing “VOR/DME, ILS, MLS, LF and HF non-directional beacons” as subject to shutdown in times of emergency. That’s quite a list, and while the technical details of the others are interesting, particularly the Adcock LF beacon system used by pilots to maneuver onto a course until alternating “A” and “N” Morse characters merged into a single tone, but for practical purposes, the one with the most impact on wartime security is the VOR system.
VOR, which stands for “VHF omnidirectional range,” is a global system of short-range beacons used by aircraft to determine their direction of travel. The system dates back to the late 1940s and was extensively built out during the post-war boom in commercial aviation. VOR stations define the “highways in the air” that criss-cross the country; if you’ve ever wondered why the contrails of jet airliners all follow similar paths and why the planes make turns at more or less the same seemingly random point in the sky, it’s because they’re using VOR beacons as waypoints.
In its simplest form, a VOR station consists of an omnidirectional antenna transmitting at an assigned frequency between 108 MHz and 117.95 MHz, hence the “VHF” designation. The frequency of each VOR station is noted on the sectional charts pilots use for navigation, along with the three-letter station identifier, which is transmitted by the station in Morse so pilots can verify which station their cockpit VOR equipment is tuned to.
Each VOR station encodes azimuth information by the phase difference between two synchronized 30 Hz signals modulated onto the carrier, a reference signal and a variable signal. In conventional VOR, the amplitude-modulated variable signal is generated by a rotating directional antenna transmitting a signal in-phase with the reference signal. By aligning the reference signal with magnetic north, the phase angle between the FM reference and AM variable signals corresponds to the compass angle of the aircraft relative to the VOR station.
More modern Doppler VORs, or DVORs, use a ring of antennas to electronically create the reference and variable signals, rather than mechanically rotating the antenna. VOR stations are often colocated with other radio navigation aids, such as distance measuring equipment (DME), which measures the propagation delay between the ground station and the aircraft to determine the distance between them, or TACAN, a tactical air navigation system first developed by the military to provide bearing and distance information. When a VOR and TACAN stations are colocated, the station is referred to as a VORTAC.
Shutting It All Down
At its peak, the VOR network around the United States numbered almost 1,000 stations. That number is on the decrease now, thanks to the FAA’s Minimum Operational Network plan, which seeks to retire all but 580 VOR stations in favor of cockpit GPS receivers. But any number of stations sweeping out fully analog, unencrypted signals on well-known frequencies would be a bonanza of navigational information to enemy airplanes, which is why the SCATANA plan provides specific procedures to be followed to shut the whole thing down.
Inside the FAA’s Washington DC ARTCC, which played a major role in implementing SCATANA on 9/11. Source: Federal Aviation Administration, public domain.
SCATANA is designed to address two types of emergencies. The first is a Defense Emergency, which is an outright attack on the United States homeland, overseas forces, or allied forces. The second is an Air Defense Emergency, which is an aircraft or missile attack on the continental U.S., Canada, Alaska, or U.S. military installations in Greenland — sorry, Hawaii. In either case, the attack can be in progress, imminent, or even just probable, as determined by high-ranking military commanders.
In both of those situations, military commanders will pass the SCATANA order to the FAA’s network of 22 Air Route Traffic Control Centers (ARTCC), the facilities that handle traffic on the routes defined by VOR stations. The SCATANA order can apply to all of the ARTCCs or to just a subset, depending on the scale of the emergency. Each of the concerned centers will then initiate physical control of their airspace, ordering all aircraft to land at the nearest available appropriate airport. Simultaneously, if ordered by military authority, the navigational aids within each ARTCC’s region will be shut down. Sufficient time is obviously needed to get planes safely to the ground; SCATANA plans allow for this, of course, but the goal is to shut down navaids as quickly as possible, to deny enemy aircraft or missiles any benefit from them.
As for the specific instructions for shutting down navigational aids, the SCATANA plan is understandable mute on this subject. It would not be advisable to have such instructions readily available, but there are a few crumbs of information available in the form of manuals and publicly accessible documents. Like most pieces of critical infrastructure these days, navaid ground stations tend to be equipped with remote control and monitoring equipment. This allows maintenance technicians quick and easy access without the need to travel. Techs can perform simple tasks, such as switching over from a defective primary transmitter to a backup, to maintain continuity of service while arrangements are made for a site visit. Given these facts, along with the obvious time-critical nature of an enemy attack, SCATANA-madated navaid shutdowns are probably as simple as a tech logging into the ground station remotely and issuing a few console commands.
A Day to Remember
For as long as SCATANA has been in effect — the earliest reference I could find to the plan under that name dates to 1968, but the essential elements of the plan seem to date back at least another 20 years — it has only been used in anger once, and even then only partially. That was on that fateful Tuesday, September 11, 2001, when a perfect crystal-blue sky was transformed into a battlefield over America.
By 9:25 AM Eastern, the Twin Towers had both been attacked, American Airlines Flight 77 had already been hijacked and was on its way to the Pentagon, and the battle for United Flight 93 was unfolding above Ohio. Aware of the scope of the disaster, staff at the FAA command center in Herndon, Virginia, asked FAA headquarters if they wanted to issue a “nationwide ground stop” order. While FAA brass discussed the matter, Ben Sliney, who had just started his first day on the job as operations manager at the FAA command center, made the fateful decision to implement the ground stop part of the SCATANA plan, without ordering the shutdown of navaids.
The “ground stop” orders went out to the 22 ARTCCs, which began the process of getting about 4,200 in-flight aircraft onto the ground as quickly and safely as possible. The ground stop was achieved within about two hours without any further incidents. The skies above the country would remain empty of civilian planes for the next two days, creating an eerie silence that emphasized just how much aviation contributes to the background noise of modern life.
Vanwege het feit dat de locatie waar de verenigingsavonden momenteel gehouden worden, niet meer voldoet aan onze verwachtingen, zijn we op zoek naar een nieuwe locatie.
We hebben enkele opties gevonden en zijn al in gesprek met één daarvan.
Tot nader order schorten we de verenigingsavonden op en informeren jullie zodra er nieuws is over een nieuwe locatie.
Op maandag 7 juli is een nieuwe remote ontvanger in gebruik genomen voor de 2 meter regiorepeater PI3ZLB. De nieuwe ontvanger staat op locatie bij PI1ZLB, in Maastricht-West (Daalhof). In de afgelopen periode zijn daarvoor een nieuwe multi-band antenne geplaatst voor 2 en 70, is de datalink naar de locatie verbeterd, en werd verouderde netwerk apparatuur vervangen.
De ontvanger is voorzien van een HA8ET 144Mhz contest preamplifier, met een ruisgetal van <0,6dB. Deze preamp heeft een IP3 van +40dBm, 60db demping voor de FM omroepband en 50dB demping op 70cm. De diplexer voegt daar nog eens 60dB aan toe op 70cm, bij een doorlaatdemping van minder dan 0,8dB.
Op basis van van de ontvangstrapporten van de 70cm repeater PI1ZLB, de antennehoogte van 124m boven N.A.P. en het vrije zicht op de wijde omgeving verwacht het repeater-team dat deze toevoeging de bereikbaarheid van de regio-reeater PI3ZLB in Maastricht en omgeving zal verbeteren.
De ingebruikname van de nieuwe ontvanger heeft geen invloed op de werking of het gebruik van de 70cm repeater PI1ZLB.
Om een goede dekking voor de repeater in het Zuid-Limburgse heuvelland te bereiken zijn, behalve een centrale ligging in Zuid-Limburg, de antennehoogte en storingsvrije omgeving belangrijke factoren. De zender in Hulsberg is weliswaar centraal gelegen, maar mist wat hoogte. De repeater is desondanks door de meeste gebruikers redelijk tot goed te ontvangen.
Voor mobiele gebruikers met laag vermogen, en gebruikers zonder buitenantenne kan het soms uitdagend zijn om over de repeater te komen. Om die reden zijn, verspreid over de regio, een aantal extra ontvangers toegevoegd:
Hulsberg – PI3ZLB
Brunssum – PA0EJH
Maastricht – PI1ZLB
Hulsberg – PE1RLN
Cadier en Keer – NL13866
TIP: Aan het aantal roger-piepjes na afloop van je uitzending kun je horen op welke ontvanger je het beste ontvanger werd, zie het lijstje hierboven.
We horen graag over je ervaringen met de bereikbaarheid van de repeaters PI3ZLB en PI1ZLB. Laat het ons weten op een clubavond.